2.7. Gidske L. Andersen: Topographic and hydrological influence on vegetation in an arid environment
2.7.1. Background
Arid lands are highly variable environments due to their water dependency and the high spatio-temporal variability of precipitation. But water is not only available to plants as run-off precipation, it is also availble as soil moisture (shallow and deep) and groundwater. These water resources are redistributed in and by the landscape. Vegetation has adapted to the variability of water resources in different ways and are found at places where water conditions are optimal, either in short term perspective (ephemeral species; where runoff is important) or in a long-term perspective (shrubs and trees; where soil moisture is stable). In this case study I will look into which topographical and hydrological parameters that influence vegetation patterns and to what degree they can model these patterns. Landsat data is used to extract vegetation indices (vegetation pattern) and SRTM is used for derivation of hydrological and topographical predictors.
The pictures below show the area for the case study in the Red Sea Hills of Sudan (an overview and a close-up to show how vegetation can grow in the wadis).
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from matplotlib import rcParams
%matplotlib inline
# figure size in inches optional
rcParams['figure.figsize'] = 11 ,8
# read images
img_A = mpimg.imread("area.jpg")
img_B = mpimg.imread("area_detail.jpg")
# display images
fig, ax = plt.subplots(1,2)
ax[0].imshow(img_A)
ax[1].imshow(img_B)
<matplotlib.image.AxesImage at 0x7f371a7f10a0>

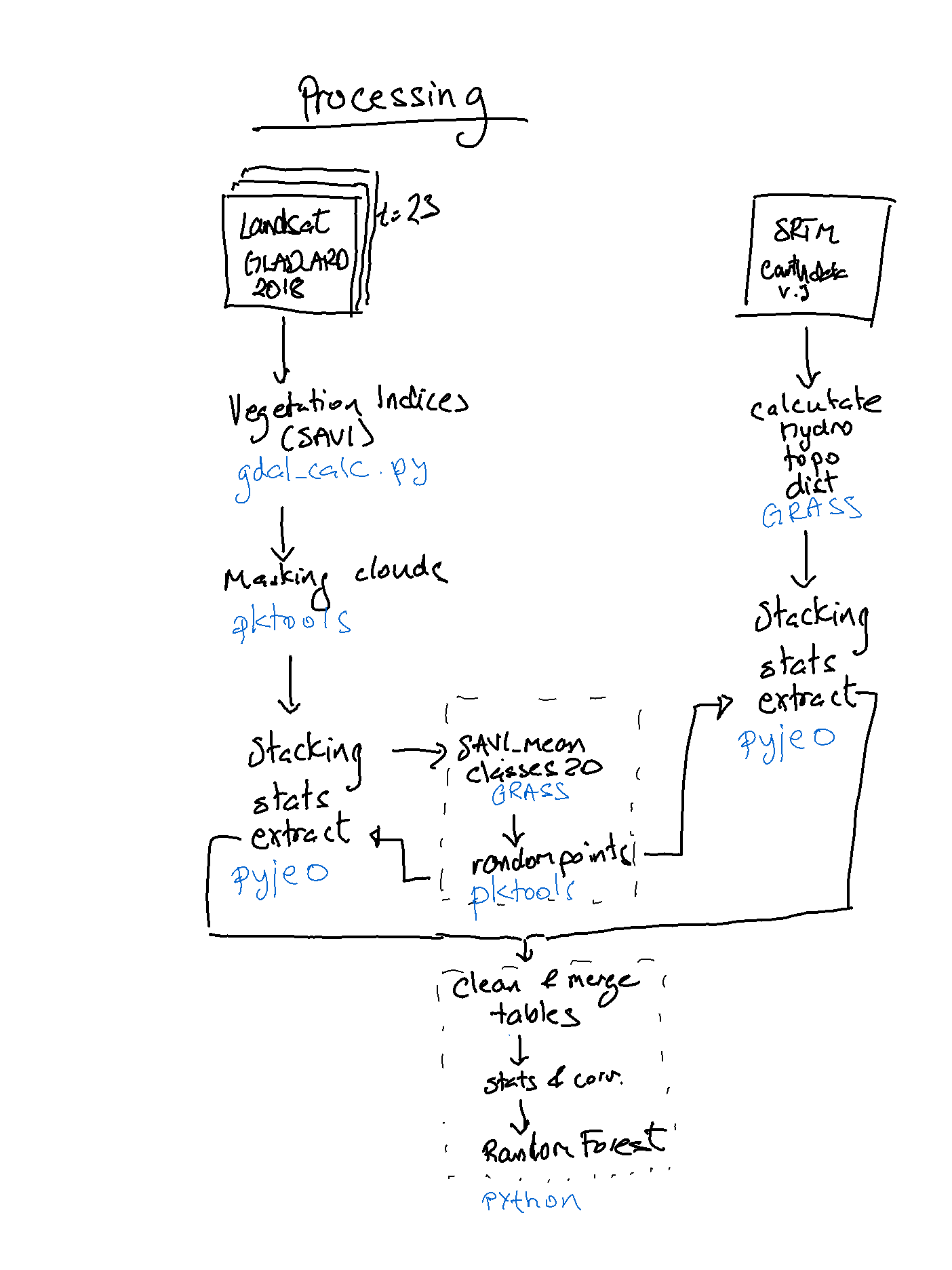
flow chart of processing
from IPython.display import Image
Image("figure_flowchart.png", width = 300)
2.7.2. 1 GLAD ARD Landsat images
The Landsat Analysis Ready Data (GLAD ARD) developed by the Global Land Analysis and Discovery (GLAD) provides spatially and temporally consistent inputs for land cover mapping and change detection. The GLAD ARD represent a 16-day time-series of tiled Landsat normalized surface reflectance from 1997 to present (source https://glad.umd.edu/book/overview).
The GLAD ARD data can be download from https://glad.umd.edu/dataset/landsat_v1.1/ previous autentifcation.
In my project I’m using imagery from Red Sea Hills, Sudan, portion of TILE 037E_18N. Due to working on the virtual machine I only selected one year of data, i.e. 2018.
The temporal series for each tile is labeled following this numerical nomenclature
first column is year
remaining columns are name of 16day time series imagery
! head -43 geodata/glad_ard/16d_intervals.csv | tail -6
2017 852 853 854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 871 872 873 874
2018 875 876 877 878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897
2019 898 899 900 901 902 903 904 905 906 907 908 909 910 911 912 913 914 915 916 917 918 919 920
2020 921 922 923 924 925 926 927 928 929 930 931 932 933 934 935 936 937 938 939 940 941 942 943
2021 944 945 946 947 948 949 950 951 952 953 954 955 956 957 958 959 960 961 962 963 964 965 966
2022 967 968 969 970 971 972 973 974 975 976 977 978 979 980 981 982 983 984 985 986 987 988 989
2.7.2.1. Data download
Data for 2018 was downloaded with this code, where user:password should be replace
%%bash
for INTER in $(grep -e ^2018 geodata/glad_ard//16d_intervals.csv | awk '{ $1=""; print $0}') ; do
curl --connect-timeout 600 -u user:passwd -X GET https://glad.umd.edu/dataset/landsat_v1.1/18N/037E_18N/$INTER.tif -o project/glad_ard/$INTER.tif
gdal_translate -co COMPRESS=DEFLATE -co ZLEVEL=9 -projwin 37 18.86666 37.4 18.63333 project/glad_ard/$INTER.tif project/glad_ard/${INTER}_crop.tif
done
The images has 8 bands, where band 3 and 4 can be used to calculate vegetation indices. Band 8, BQA, is used for masking pixels with low quality (https://glad.umd.edu/ard/landsat-ard-methodology). In addition to clouds, there can also be low quality pixels seen as stripes (caused by sensor problems; see figure below).
Due the arid characteristics of the area, the Soil Adjusted Vegetation Index (SAVI) is used:
(NIR - Red)/(NIR + RED) + 0.5)) * 1.5
%%capture
#converting to png for display
!gdal_translate -b 1 -b 2 -b 3 project/glad_ard/875_crop.tif project/glad_ard/875_crop.png
from rasterio.plot import show
src = rasterio.open("project/glad_ard/875_crop_m.tif")
show(src, cmap='pink')

<matplotlib.axes._subplots.AxesSubplot at 0x7f3719b14eb0>
2.7.2.2. Calculate vegetation index
%%bash
for file in project/glad_ard/*_crop.tif; do
filename=$(basename $file .tif )
#echo $file
#VI
gdal_calc.py --type=Float32 --overwrite -A $file --A_band=3 -B $file --B_band=4 \
--co COMPRESS=DEFLATE --co ZLEVEL=9 --calc="(B.astype(float))/(A.astype(float))" --outfile=project/glad_ard/${filename}_VI.tif \
--quiet
#NDVI
gdal_calc.py --type=Float32 --overwrite -A $file --A_band=3 -B $file --B_band=4 \
--co COMPRESS=DEFLATE --co ZLEVEL=9 --calc="(B.astype(float)- A.astype(float))/(B.astype(float) + A.astype(float))" \
--outfile=project/glad_ard/${filename}_NDVI.tif \
--quiet
#SAVI
gdal_calc.py --type=Float32 --overwrite -A $file --A_band=3 -B $file --B_band=4 \
--co COMPRESS=DEFLATE --co ZLEVEL=9 --calc="((B.astype(float)- A.astype(float))/(B.astype(float) + A.astype(float) + 0.5)) * 1.5" \
--outfile=project/glad_ard/${filename}_SAVI.tif \
--quiet
done
2.7.2.3. Masking and statistics
Only BQA pixels 1 and 2 are kept in the masking. Since counting starts from 0, BQA band is #7. Nodata value is set to Uint16 max (65535) since using 0 will cause error when estimating SAVI. All images were masked in the same way after calculating SAVI (since input nulldata could not be set in this version of gdalcalc.py).
%%capture
%%bash
for file in project/glad_ard/*_crop.tif; do
filename=$(basename $file .tif )
echo $file
echo $filename
pkgetmask --overwrite -i $file -o project/glad_ard/${filename}_mask.tif -min 1 -max 2 -b 7
pksetmask -i project/glad_ard/${filename}_SAVI.tif -m project/glad_ard/${filename}_mask.tif -msknodata 0 -nodata -99 \
-o project/glad_ard/${filename}_SAVI_m.tif\
--quiet
done
Checking nodata and statistics for the VIs
%%bash
gdalinfo project/glad_ard/875_crop_SAVI_m.tif |grep -E 'NoData'
NoData Value=-99
%%bash
for file in project/glad_ard/*crop_SAVI_m.tif; do
pkinfo -i $file -stats|awk '{print $0}'
done
-min -0.211417 -max 0.611614 --mean 0.12386 --stdDev 0.0465675
-min 0.0631748 -max 0.210848 --mean 0.134271 --stdDev 0.0229662
-min -0.188215 -max 0.772617 --mean 0.126266 --stdDev 0.0579652
-min -0.31516 -max 0.715421 --mean 0.126566 --stdDev 0.0513284
-min -0.216388 -max 0.600698 --mean 0.124193 --stdDev 0.0397357
-min -0.274006 -max 0.610294 --mean 0.124246 --stdDev 0.0368988
-min -0.227176 -max 0.60059 --mean 0.124319 --stdDev 0.0350922
-min -0.0308992 -max 0.572593 --mean 0.123665 --stdDev 0.0308838
-min -0.197234 -max 0.620289 --mean 0.128406 --stdDev 0.0353955
-min -0.0114275 -max 0.636907 --mean 0.125323 --stdDev 0.0319995
-min 0.063293 -max 0.226574 --mean 0.11956 --stdDev 0.0187572
-min 0.07592 -max 0.250311 --mean 0.122435 --stdDev 0.019505
-min -0.00347078 -max 0.500646 --mean 0.127181 --stdDev 0.0314407
-min 0.0270167 -max 0.394247 --mean 0.128143 --stdDev 0.0302831
-min -0.0294599 -max 0.542999 --mean 0.125114 --stdDev 0.0315137
-min 0.0247256 -max 0.229192 --mean 0.109571 --stdDev 0.0199349
-min -0.234899 -max 0.79372 --mean 0.125687 --stdDev 0.0335479
-min -0.526694 -max 0.911127 --mean 0.126048 --stdDev 0.0363183
-min -0.105182 -max 0.686265 --mean 0.132825 --stdDev 0.030873
-min -0.307845 -max 0.969288 --mean 0.132675 --stdDev 0.0423124
-min -0.169741 -max 0.699102 --mean 0.135448 --stdDev 0.0472854
-min -0.41313 -max 0.955517 --mean 0.168209 --stdDev 0.0908494
-min -0.0180593 -max 0.620982 --mean 0.134354 --stdDev 0.0493728
-min -0.186645 -max 0.349589 --mean 0.1139 --stdDev 0.037978
Extracting histograms for SAVI
%%capture
%%bash
for file in project/glad_ard/*_SAVI_m.tif; do
filename=$(basename $file .tif )
echo $filename
pkstat -i $file -hist -nbin 20 -nodata -99 > project/glad_ard/${filename}_h.txt
done
!more project/glad_ard/897_crop_SAVI_m_h.txt
-0.002083286643 7
0.02986876667 154
0.06182081997 6017
0.09377287328 44899
0.1257249266 33275
0.1576769799 15828
0.1896290332 7138
0.2215810865 3958
0.2535331398 1774
0.2854851931 1003
0.3174372464 313
0.3493892998 218
0.3813413531 134
0.4132934064 86
0.4452454597 45
0.477197513 31
0.5091495663 20
0.5411016196 9
0.5730536729 5
0.6050057262 2
2.7.3. Generate stacks and extract statistics in Pyjeo
I wanted to try out Pyjeo after Dr. Pieter Kempeneers presentation (http://spatial-ecology.net/docs/build/html/PKTOOLS/pyjeo_introduction.html). I used it to calculate yearly mean, median, 90 percentil and standard deviation. Probably there are cleaner ways to do this with some more pyjeo-practice. One of workarounds I ended up using was creating a test* jim, and copied crs++ info from that to an “empty” jim that was “filled” with all my timesteps/planes. Later I used these layers when extracting information for random points.
from pathlib import Path
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import pyjeo as pj
import os
fn = Path('project/glad_ard/875_crop_SAVI_m.tif')
test = pj.Jim(fn)
#del jim #delete if old jim exists
jim = pj.Jim(ncol = 1600, nrow = 933, otype='float32', nodata=-99) #create jim object with one 1 empty plane
jim.properties.copyGeoTransform(test) #get all crs from test
print(jim.properties.nrOfCol())
print(jim.properties.getBBox())
print(jim.stats.getStats())
print(jim.properties.nrOfPlane()) #show number of planes
1600
[37.0, 18.86675, 37.4, 18.633499999999998]
{'min': 0.0, 'max': 0.0, 'mean': 0.0}
1
# iterate over SAVI files in
# that directory
#check number of files/planes
!ls project/glad_ard/???_crop_SAVI_m.tif | wc -l
#sjekk denne sorteringen
files = sorted(Path('project/glad_ard').glob('???_crop_SAVI_m.tif'))
for file in files:
jim.geometry.stackPlane(pj.Jim(file))
print(jim.properties.nrOfPlane()) #show number of planes
#remove first empty plane; probably better way to do this
jim=jim[[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23]]
jim.properties.nrOfPlane() #should be 23
23
24
23
print(jim.stats.getStats())
{'min': -99.0, 'max': 0.9692878723144531, 'mean': -25.83536720275879}
#calculate mean
mean = pj.geometry.reducePlane(jim, rule = 'mean', nodata = -99.0) #applied mask to all planes (more than 2D); "reduce" som i GEE
mean.stats.getStats()
{'min': -0.02188333310186863,
'max': 0.5145996809005737,
'mean': 0.12636782228946686}
#calculate median
median = pj.geometry.reducePlane(jim, rule = 'median', nodata = -99)
median.stats.getStats()
{'min': -0.006859873421490192,
'max': 0.5675770044326782,
'mean': 0.12463919818401337}
#calculate stdev
# std.pixops.convert('GDT_Float32') #converts into float if needed
std = pj.Jim(mean) #works as a placeholder for the std to be calculated
jim.np()[jim.np()==-99] = np.nan #all 0 assign to nan
stdnp = np.nanstd(jim.np(), axis=0) #second data cube (1), starts at 0
std.np()[:] = stdnp
std.stats.getStats()
{'min': 0.001729343319311738,
'max': 0.2672453820705414,
'mean': 0.017469022423028946}
#calculate quantiles
per90 = pj.Jim(mean)
jim.np()[jim.np()==-99] = np.nan #all -99 assign to nan
per90np = np.nanpercentile(jim.np(), 90, axis=0)
per90.np()[:] = per90np
per90.stats.getStats()
{'min': 0.06932799518108368,
'max': 0.9273030161857605,
'mean': 0.14474131166934967}
plt.gray() # show the filtered result in grayscale
fig = plt.figure(figsize=(20,10))
ax1 = fig.add_subplot(141)
ax2 = fig.add_subplot(142)
ax3 = fig.add_subplot(143)
ax4 = fig.add_subplot(144)
ax1.imshow(mean.np())
ax2.imshow(std.np())
ax3.imshow(per90.np())
ax4.imshow(median.np())
plt.show()
<Figure size 432x288 with 0 Axes>

#save to files
mean.io.write('project/glad_ard/mean_pyjeo.tif', co = ['COMPRESS=DEFLATE', 'ZLEVEL=9']) #io from io-module
median.io.write('project/glad_ard/median_pyjeo.tif', co = ['COMPRESS=DEFLATE', 'ZLEVEL=9']) #io from io-module
std.io.write('project/glad_ard/std_pyjeo.tif', co = ['COMPRESS=DEFLATE', 'ZLEVEL=9']) #io from io-module
per90.io.write('project/glad_ard/per90_pyjeo.tif', co = ['COMPRESS=DEFLATE', 'ZLEVEL=9']) #io from io-module
2.7.4. 2 Creating topographical and hydrological layers in GRASS
Requirements for GRASS to run
make seperate folder under home/user/ to run GRASS
install addons for special algorithms, i.e. r.stream.order. Addons had to be downloaded from github to be installed due to changes in URL not implemented in current version of GRASS (7.8.5).
%%bash
mkdir -p /home/user/my_SE_data/exercise
cp -r /home/user/SE_data/exercise/grassdb /home/user/my_SE_data/exercise
git clone https://github.com/OSGeo/grass-addons.git /home/user/grass_addons
#run GRASS to install extension
cd /home/user/my_SE_data/exercise
grass78 -text grassdb/europe/PERMANENT/ << EOF
g.extension extension=r.stream.basins url=/home/user/grass_addons/src/raster/r.stream.basins/
g.extension extension=r.stream.distance url=/home/user/grass_addons/src/raster/r.stream.distance/
EOF
2.7.4.1. Download SRTM
SRTM data (version 3, 30m resolution) was downloaded from NASA earthdata.
See https://wiki.earthdata.nasa.gov/display/EL/How+To+Access+Data+With+cURL+And+Wget
Replace “user” and “password”
%%bash
cd /home/user/
touch .netrc
echo "machine urs.earthdata.nasa.gov login <user> password <password>" > .netrc
chmod 0600 .netrc
#### create cookie ####
cd ~
touch .urs_cookies
##### download more files in one go and move to folder ####
curl -O -b ~/.urs_cookies -c ~/.urs_cookies -L -n "https://e4ftl01.cr.usgs.gov/MEASURES/SRTMGL1.003/2000.02.11/N18E0[36-37].SRTMGL1.hgt.zip"
mv N18* project/srtm/
cd project/srtm/
unzip "*.zip"
##### to speed up convert to tiff ####
for file in project/srtm/*.hgt; do
filename=$(basename $file .hgt)
gdal_translate -co COMPRESS=DEFLATE -co ZLEVEL=9 -co PREDICTOR=2 $file project/srtm/$filename.tif
done
2.7.4.2. Calculate variables
A number of topographic and hydrological explanatory variables are calculated in GRASS. Since some of the hydrological variables are depending on data for complete watersheds, region is readjusted to the smaller AOI (from landsat savi data) when the export is done (g.region). Distance from streams and stream junctions are also calculated.
%%capture
%%bash
# topidx don't work on lat lon data
cp project/srtm/N18E037.tif /home/user/my_SE_data/exercise/
cd /home/user/my_SE_data/exercise
mkdir grassout
# use the --tmp-location option to store a temporal location in the /tmp folder
# -f forces removal of gislock; --text - textbased GUI --tmp-location - temporary location deleted
# -c geofile - location based on that file
# opens a GRASS text interface where input is ended by EOF
grass78 -f -text --tmp-location -c /home/user/my_SE_data/exercise/N18E037.tif <<'EOF'
#prints all env. settings
#debug 0 - silence
g.gisenv set="GRASS_VERBOSE=-1","DEBUG=0"
echo "######## import the layers ########"
# not imported, just registered as a grass dataset
r.external input=N18E037.tif output=elv --o --q # dem
r.external input=landsat/SAVI.tif output=savi --o --q
echo "######## calculate topographic layers ########"
r.slope.aspect elevation=elv slope=slope aspect=aspect pcurvature=pcurv tcurvature=tcurv dx=dx dy=dy dxx=dxx dyy=dyy dxy=dxy --o
#r.topidx input=elv output=topidx --o
echo "######## estimating watershed ########"
#threshold basinsize in number of pixels
r.watershed elevation=elv threshold=2000 \
accumulation=w_accum \
tci=w_tci \
spi=w_spi \
drainage=w_dr_dir \
basin=w_basin \
stream=w_stream_w2k \
length_slope=w_lSl \
slope_steepness=w_SlSt \
--o
echo "######## estimating distance from stream ########"
# input should be from same function (r.watershed or r.stream..)
r.stream.distance stream_rast=w_stream_w2k \
direction=w_dr_dir \
elevation=elv \
method=downstream \
distance=w_str_w2k_dist
echo "######## extract stream vector ########"
# extract stream vector, including points for confluence
r.stream.extract elevation=elv \
accumulation=w_accum \
threshold=2000 \
stream_vector=streamx_2kv \
--o
echo "######## info stream vector ########"
#info about stream_v
db.describe -c table=streamx_2kv
v.to.rast input=streamx_2kv type=point where="type_code = 1" output=str_2kvj_r use=attr attribute_column="type_code"
echo "######## estimating distance from junctions ########"
#-m for meter
r.grow.distance -m input=str_2kvj_r distance=str_2kvj_dist metric=geodesic
echo "######## exporting products ########"
#export multiple rasterfiles - exclude elv from the list
g.region raster=savi
for file in $(g.list type=raster ); do
r.out.gdal --o -f -c -m createopt="COMPRESS=DEFLATE,ZLEVEL=9" type=Float64 nodata=999999999 format=GTiff input=$file output=grassout/${file}.tif
done
EOF
2.7.5. 3 Extract statistics for random points
Random points are created within classes of SAVI_mean to make sure the whole range of SAVI values are represented. The SAVI classes are based on the histogram with 20 bins. Classfication of SAVI is done in GRASS using a file with the recoding values. Awk is used to generate the recode.txt file, that should . have the following format:
1:1:1.1:1.1 #from_start:from_end:to_start:to_end, where to_start=to_end for classes.
Random points are generated with pkextractimg.
#del jim
fn = Path('project/glad_ard/mean_pyjeo.tif')
jim = pj.Jim(fn)
jim.stats.getStats()
{'min': -0.02188333310186863,
'max': 0.5159205794334412,
'mean': 0.1263299584388733}
!rm -r output.txt
stats = jim.stats.getStats('histogram', nbin=20, src_min=-0.1, src_max=0.55, nodata=-99)
with open("output.txt", "a") as f:
for index, bin in enumerate(stats['bin']):
print(bin, stats['histogram'][index], file=f)
%%bash
#make recode rules from txt-file
paste -d":" \
<(awk '{print $1}' output.txt | head -n19) \
<(awk 'NR>1{print $1}' output.txt) \
<(printf "%s\n" {1..19}) \
<(printf "%s\n" {1..19}) \
> rules.txt
!wc -l rules.txt
!more rules.txt
19 rules.txt
-0.08375:-0.05125:1:1
-0.05125:-0.01875:2:2
-0.01875:0.01375:3:3
0.01375:0.04625:4:4
0.04625:0.07875:5:5
0.07875:0.11125:6:6
0.11125:0.14375:7:7
0.14375:0.17625:8:8
0.17625:0.20875:9:9
0.20875:0.24125:10:10
0.24125:0.27375:11:11
0.27375:0.30625:12:12
0.30625:0.33875:13:13
0.33875:0.37125:14:14
0.37125:0.40375:15:15
0.40375:0.43625:16:16
0.43625:0.46875:17:17
0.46875:0.50125:18:18
0.50125:0.53375:19:19
classify SAVI with GRASS
%%capture
%%bash
cp project/glad_ard/mean_pyjeo.tif /home/user/my_SE_data/exercise/
cd /home/user/my_SE_data/exercise
grass78 -f -text --tmp-location -c /home/user/my_SE_data/exercise/mean_pyjeo.tif <<'EOF'
g.gisenv set="GRASS_VERBOSE=-1","DEBUG=0"
echo "######## import the layers #############"
r.external input=mean_pyjeo.tif output=SAVI --o --q # dem
echo "######## recode SAVI 30classes #############"
r.recode input=SAVI output=SAVI_c rules=rules.txt
r.out.gdal --o -f -c -m createopt="COMPRESS=DEFLATE,ZLEVEL=9" format=GTiff input=SAVI_c output=SAVI_c.tif
EOF
create random points
!pkextractimg -i project/glad_ard/mean_pyjeo.tif \
-s project/glad_ard/SAVI_c.tif \
-o project/glad_ard/random.sqlite -t 5
!ogrinfo project/glad_ard/random.sqlite
- 'VirtualXPath' [XML Path Language - XPath]
INFO: Open of `project/glad_ard/random.sqlite'
using driver `SQLite' successful.
1: training data (Point)
2.7.5.1. Extract values for response and predictor variables
In this part values for predictors and response variables for all random points are extracted. I’m using pyjeo for this part. Since stacking requires the datasets to be same datatype as well as CRS, extraction is done separately for response and predictors.
Repsonse variable
del jim
jim = pj.Jim(ncol = 1600, nrow = 933, otype='float32', nodata=-99) #create empty jim object
jim.properties.copyGeoReference(test)
print(jim.properties.nrOfCol())
print(jim.properties.getBBox())
print(jim.stats.getStats())
files = sorted(Path('project/glad_ard').glob('*pyjeo.tif'))
print(files)
for file in files:
jim.geometry.stackPlane(pj.Jim(file))
jim.properties.nrOfPlane() #show number of planes
jim=jim[[1,2,3,4]] #select last 4 planes
1600
[37.0, 18.86675, 37.4, 18.633499999999998]
{'min': 0.0, 'max': 0.0, 'mean': 0.0}
[PosixPath('project/glad_ard/mean_pyjeo.tif'), PosixPath('project/glad_ard/median_pyjeo.tif'), PosixPath('project/glad_ard/per90_pyjeo.tif'), PosixPath('project/glad_ard/std_pyjeo.tif')]
#check CRS for layers
!ogrinfo -so project/glad_ard/random.sqlite 'training data' | grep -E 'EPSG'
!gdalinfo project/glad_ard/mean_pyjeo.tif | grep -E 'EPSG'
jim.properties.getProjection()
#test.properties.getProjection()
ID["EPSG",4326]]
'GEOGCS["WGS 84",DATUM["WGS_1984",SPHEROID["WGS 84",6378137,298.257223563,AUTHORITY["EPSG","7030"]],AUTHORITY["EPSG","6326"]],PRIMEM["Greenwich",0],UNIT["degree",0.0174532925199433,AUTHORITY["EPSG","9122"]],AXIS["Latitude",NORTH],AXIS["Longitude",EAST],AUTHORITY["EPSG","4326"]]'
vfn = 'project/glad_ard/random.sqlite'
v = pj.JimVect(vfn)
output = 'project/glad_ard/temp.sqlite'
Path(output).unlink(missing_ok = True)
extracted1 = pj.geometry.extract(v, jim, output=output, srcnodata = -99)
savi = pd.DataFrame(extracted1.dict())
savi.to_csv('project/glad_ard/savi.csv')
Predictor variables
fn = Path('/home/user/my_SE_data/exercise/grassout/elv.tif')
del jim #if old jim exists
jim = pj.Jim(fn)
planes = jim.properties.nrOfPlane()
col = jim.properties.nrOfCol() #show number of planes; i.e. timesteps
row = jim.properties.nrOfRow()
print('no of planes, columns and rows:',planes, col, row)
no of planes, columns and rows: 1 1600 933
print(jim.properties.getBBox())
print(jim.stats.getStats())
[37.0, 18.86675, 37.4, 18.633499999999998]
{'min': 6.0, 'max': 1530.0, 'mean': 576.3270136655949}
%%capture
%%bash
#planes to be added
ls /home/user/my_SE_data/exercise/grassout/*.tif | wc -l
#check that all rasters are same datatype
for file in /home/user/my_SE_data/exercise/grassout/*.tif; do
echo $file
gdalinfo $file -stats | grep -E 'Type' | awk '{print $4}'
done
# iterate over tif files in
# that directory
files = sorted(Path('/home/user/my_SE_data/exercise/grassout').glob('*.tif'))
print(files)
for file in files:
jim.geometry.stackPlane(pj.Jim(file))
planes = jim.properties.nrOfPlane()
col = jim.properties.nrOfCol()
row = jim.properties.nrOfRow()
print('no of files, no of planes, columns and rows:',len(files), planes, col, row)
[PosixPath('/home/user/my_SE_data/exercise/grassout/aspect.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/dx.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/dxx.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/dxy.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/dy.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/dyy.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/elv.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/pcurv.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/savi.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/slope.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/str_2kvj_dist.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/str_2kvj_r.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/tcurv.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_SlSt.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_accum.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_basin.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_dr_dir.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_lSl.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_spi.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_str_w2k_dist.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_stream_w2k.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_tci.tif')]
no of files, no of planes, columns and rows: 22 23 1600 933
!ogrinfo -so project/glad_ard/random.sqlite 'training data' | grep -E 'EPSG'
# confirm that CRS is the same
jim.properties.getProjection()
ID["EPSG",4326]]
'GEOGCS["WGS 84",DATUM["WGS_1984",SPHEROID["WGS 84",6378137,298.257223563,AUTHORITY["EPSG","7030"]],AUTHORITY["EPSG","6326"]],PRIMEM["Greenwich",0],UNIT["degree",0.0174532925199433,AUTHORITY["EPSG","9122"]],AXIS["Latitude",NORTH],AXIS["Longitude",EAST],AUTHORITY["EPSG","4326"]]'
vfn = 'project/glad_ard/random.sqlite'
v = pj.JimVect(vfn)
output = 'project/glad_ard/temp1.sqlite'
Path(output).unlink(missing_ok = True)
extracted3 = pj.geometry.extract(v, jim, output=output, srcnodata = 999999999)
topo = pd.DataFrame(extracted3.dict())
topo.to_csv('project/glad_ard/predictors.csv')
topo.head()
| fid | label | b | t0b0 | t1b0 | t2b0 | t3b0 | t4b0 | t5b0 | t6b0 | ... | t13b0 | t14b0 | t15b0 | t16b0 | t17b0 | t18b0 | t19b0 | t20b0 | t21b0 | t22b0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 11 | 0.097008 | 760.0 | 167.750107 | -0.243415 | -0.006419 | -0.000278 | 0.052850 | -0.003702 | ... | -0.003823 | 16.299999 | 57.580921 | 298.0 | 3.0 | 0.078407 | 173.928513 | 42.452179 | 1.000000e+09 | 8.741459 |
| 1 | 1 | 10 | 0.082413 | 793.0 | 186.597610 | -0.456937 | -0.003307 | -0.001944 | -0.052850 | -0.005112 | ... | -0.004220 | 16.299999 | 18.216928 | 298.0 | 5.0 | 0.040093 | 153.324326 | 143.446518 | 1.000000e+09 | 7.134220 |
| 2 | 2 | 10 | 0.082921 | 808.0 | 187.867950 | -0.529534 | -0.002334 | 0.000556 | -0.073177 | -0.004231 | ... | -0.003833 | 16.299999 | 13.026308 | 298.0 | 5.0 | 0.054766 | 115.282860 | 199.080109 | 1.000000e+09 | 6.180274 |
| 3 | 3 | 11 | 0.106816 | 877.0 | 135.514297 | -0.269037 | -0.004474 | 0.001944 | 0.264250 | -0.000881 | ... | -0.000656 | 0.030000 | 5.122952 | 298.0 | 3.0 | 0.030000 | 23.608582 | 824.232788 | 1.000000e+09 | 5.899572 |
| 4 | 4 | 11 | 0.114286 | 898.0 | 95.767517 | -0.042704 | -0.003501 | 0.001667 | 0.422801 | -0.003173 | ... | -0.002913 | 16.299999 | 2.950633 | 298.0 | 2.0 | 0.037655 | 23.699802 | 1175.459473 | 1.000000e+09 | 5.373617 |
5 rows × 26 columns
2.7.6. 4 Modelling vegetation
import pandas as pd
import numpy as np
import rasterio
from rasterio import * #raster processing
from rasterio.plot import show
from pyspatialml import Raster
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.pipeline import Pipeline
from scipy.stats import pearsonr
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (10,6.5)
import seaborn as sns
2.7.6.1. Prepare table
import table and rename predictor variables
#read data using panda
predictors = pd.read_csv("project/glad_ard/predictors.csv", sep=",", index_col=False)
pd.set_option('display.max_columns',None)
predictors.columns
Index(['Unnamed: 0', 'fid', 'label', 'b', 't0b0', 't1b0', 't2b0', 't3b0',
't4b0', 't5b0', 't6b0', 't7b0', 't8b0', 't9b0', 't10b0', 't11b0',
't12b0', 't13b0', 't14b0', 't15b0', 't16b0', 't17b0', 't18b0', 't19b0',
't20b0', 't21b0', 't22b0'],
dtype='object')
!ls /home/user/my_SE_data/exercise/grassout/*.tif | xargs -n1 basename
aspect.tif
dx.tif
dxx.tif
dxy.tif
dy.tif
dyy.tif
elv.tif
pcurv.tif
savi.tif
slope.tif
str_2kvj_dist.tif
str_2kvj_r.tif
tcurv.tif
w_accum.tif
w_basin.tif
w_dr_dir.tif
w_lSl.tif
w_SlSt.tif
w_spi.tif
w_stream_w2k.tif
w_str_w2k_dist.tif
w_tci.tif
print(files)
len(files)
[PosixPath('/home/user/my_SE_data/exercise/grassout/aspect.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/dx.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/dxx.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/dxy.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/dy.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/dyy.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/elv.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/pcurv.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/savi.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/slope.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/str_2kvj_dist.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/str_2kvj_r.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/tcurv.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_SlSt.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_accum.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_basin.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_dr_dir.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_lSl.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_spi.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_str_w2k_dist.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_stream_w2k.tif'), PosixPath('/home/user/my_SE_data/exercise/grassout/w_tci.tif')]
22
#PS! sorting gave different results for jim object and in bash (capital letters?)
names_list = ['aspect', 'dx', 'dxx', 'dxy', 'dy', 'dyy', 'elv', 'pcurv', 'savi', 'slope',
'str_2kvj_dist', 'str_2kvj_r', 'tcurv', 'w_SlSt', 'w_accum',
'w_basin', 'w_dr_dir', 'w_lSl', 'w_spi', 'w_str_w2k_dist', 'w_stream_w2k', 'w_tci']
len(names_list)
print(predictors.columns)
len(predictors.columns)
Index(['Unnamed: 0', 'fid', 'label', 'b', 't0b0', 't1b0', 't2b0', 't3b0',
't4b0', 't5b0', 't6b0', 't7b0', 't8b0', 't9b0', 't10b0', 't11b0',
't12b0', 't13b0', 't14b0', 't15b0', 't16b0', 't17b0', 't18b0', 't19b0',
't20b0', 't21b0', 't22b0'],
dtype='object')
27
predictors.columns = predictors.columns[:5].tolist() + names_list
print(predictors.columns)
Index(['Unnamed: 0', 'fid', 'label', 'b', 't0b0', 'aspect', 'dx', 'dxx', 'dxy',
'dy', 'dyy', 'elv', 'pcurv', 'savi', 'slope', 'str_2kvj_dist',
'str_2kvj_r', 'tcurv', 'w_SlSt', 'w_accum', 'w_basin', 'w_dr_dir',
'w_lSl', 'w_spi', 'w_str_w2k_dist', 'w_stream_w2k', 'w_tci'],
dtype='object')
len(predictors)
74610
predictors.head()
| Unnamed: 0 | fid | label | b | t0b0 | aspect | dx | dxx | dxy | dy | dyy | elv | pcurv | savi | slope | str_2kvj_dist | str_2kvj_r | tcurv | w_SlSt | w_accum | w_basin | w_dr_dir | w_lSl | w_spi | w_str_w2k_dist | w_stream_w2k | w_tci | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 11 | 0.097008 | 760.0 | 167.750107 | -0.243415 | -0.006419 | -0.000278 | 0.052850 | -0.003702 | 760.0 | -0.005648 | 0.086638 | 13.986955 | 1611.938110 | 1.000000e+09 | -0.003823 | 16.299999 | 57.580921 | 298.0 | 3.0 | 0.078407 | 173.928513 | 42.452179 | 1.000000e+09 | 8.741459 |
| 1 | 1 | 1 | 10 | 0.082413 | 793.0 | 186.597610 | -0.456937 | -0.003307 | -0.001944 | -0.052850 | -0.005112 | 793.0 | -0.002830 | 0.083820 | 24.701620 | 1603.144653 | 1.000000e+09 | -0.004220 | 16.299999 | 18.216928 | 298.0 | 5.0 | 0.040093 | 153.324326 | 143.446518 | 1.000000e+09 | 7.134220 |
| 2 | 2 | 2 | 10 | 0.082921 | 808.0 | 187.867950 | -0.529534 | -0.002334 | 0.000556 | -0.073177 | -0.004231 | 808.0 | -0.001522 | 0.083765 | 28.127462 | 1601.273193 | 1.000000e+09 | -0.003833 | 16.299999 | 13.026308 | 298.0 | 5.0 | 0.054766 | 115.282860 | 199.080109 | 1.000000e+09 | 6.180274 |
| 3 | 3 | 3 | 11 | 0.106816 | 877.0 | 135.514297 | -0.269037 | -0.004474 | 0.001944 | 0.264250 | -0.000881 | 877.0 | -0.003813 | 0.130181 | 20.661793 | 1625.434448 | 1.000000e+09 | -0.000656 | 0.030000 | 5.122952 | 298.0 | 3.0 | 0.030000 | 23.608582 | 824.232788 | 1.000000e+09 | 5.899572 |
| 4 | 4 | 4 | 11 | 0.114286 | 898.0 | 95.767517 | -0.042704 | -0.003501 | 0.001667 | 0.422801 | -0.003173 | 898.0 | -0.002736 | 0.139849 | 23.023153 | 1658.049072 | 1.000000e+09 | -0.002913 | 16.299999 | 2.950633 | 298.0 | 2.0 | 0.037655 | 23.699802 | 1175.459473 | 1.000000e+09 | 5.373617 |
Cleaing up table and calculate some new variables
Columns that will not be used in the modelling is deleted from the table. Aspect is a circular variable and is linearised by calculating its sine and cosine. w_basin is a categorical value and to test whether it is treated correctly and meaningful its values are shuffled (basin_shuf).
predictors = predictors.drop(['Unnamed: 0', 'b', 't0b0', 'w_stream_w2k', 'savi', 'str_2kvj_r'], axis=1)
predictors.columns
Index(['fid', 'label', 'aspect', 'dx', 'dxx', 'dxy', 'dy', 'dyy', 'elv',
'pcurv', 'slope', 'str_2kvj_dist', 'tcurv', 'w_SlSt', 'w_accum',
'w_basin', 'w_dr_dir', 'w_lSl', 'w_spi', 'w_str_w2k_dist', 'w_tci'],
dtype='object')
#linearise aspect
import numpy as np
predictors['cos_asp']=np.cos(np.radians(predictors['aspect']))
predictors['sin_asp']=np.sin(np.radians(predictors['aspect']))
#shuffle categorical basin-variable
predictors['basin_shuf'] = np.random.permutation(predictors['w_basin'].values)
predictors.head()
| fid | label | aspect | dx | dxx | dxy | dy | dyy | elv | pcurv | slope | str_2kvj_dist | tcurv | w_SlSt | w_accum | w_basin | w_dr_dir | w_lSl | w_spi | w_str_w2k_dist | w_tci | cos_asp | sin_asp | basin_shuf | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 11 | 167.750107 | -0.243415 | -0.006419 | -0.000278 | 0.052850 | -0.003702 | 760.0 | -0.005648 | 13.986955 | 1611.938110 | -0.003823 | 16.299999 | 57.580921 | 298.0 | 3.0 | 0.078407 | 173.928513 | 42.452179 | 8.741459 | -0.977232 | 0.212176 | 7490.0 |
| 1 | 1 | 10 | 186.597610 | -0.456937 | -0.003307 | -0.001944 | -0.052850 | -0.005112 | 793.0 | -0.002830 | 24.701620 | 1603.144653 | -0.004220 | 16.299999 | 18.216928 | 298.0 | 5.0 | 0.040093 | 153.324326 | 143.446518 | 7.134220 | -0.993378 | -0.114896 | 1646.0 |
| 2 | 2 | 10 | 187.867950 | -0.529534 | -0.002334 | 0.000556 | -0.073177 | -0.004231 | 808.0 | -0.001522 | 28.127462 | 1601.273193 | -0.003833 | 16.299999 | 13.026308 | 298.0 | 5.0 | 0.054766 | 115.282860 | 199.080109 | 6.180274 | -0.990586 | -0.136890 | 6642.0 |
| 3 | 3 | 11 | 135.514297 | -0.269037 | -0.004474 | 0.001944 | 0.264250 | -0.000881 | 877.0 | -0.003813 | 20.661793 | 1625.434448 | -0.000656 | 0.030000 | 5.122952 | 298.0 | 3.0 | 0.030000 | 23.608582 | 824.232788 | 5.899572 | -0.713425 | 0.700731 | 1154.0 |
| 4 | 4 | 11 | 95.767517 | -0.042704 | -0.003501 | 0.001667 | 0.422801 | -0.003173 | 898.0 | -0.002736 | 23.023153 | 1658.049072 | -0.002913 | 16.299999 | 2.950633 | 298.0 | 2.0 | 0.037655 | 23.699802 | 1175.459473 | 5.373617 | -0.100492 | 0.994938 | 1172.0 |
import response variable and join to predictors
#read response using panda
savi = pd.read_csv("project/glad_ard/savi.csv", sep=",", index_col=False)
pd.set_option('display.max_columns',None)
print(savi.columns)
savi = savi.rename({'t0b0':'mean',
't1b0':'median',
't2b0':'per90',
't3b0':'std'
} , axis='columns')
savi = savi.drop(['Unnamed: 0', 'b', 'label'], axis=1)
savi.head(10)
print(len(savi))
print(savi.columns)
Index(['Unnamed: 0', 'fid', 'label', 'b', 't0b0', 't1b0', 't2b0', 't3b0'], dtype='object')
74610
Index(['fid', 'mean', 'median', 'per90', 'std'], dtype='object')
predictors = predictors.merge(savi, left_on = 'fid', right_on='fid', how = 'inner')
len(predictors)
74610
predictors.head()
| fid | label | aspect | dx | dxx | dxy | dy | dyy | elv | pcurv | slope | str_2kvj_dist | tcurv | w_SlSt | w_accum | w_basin | w_dr_dir | w_lSl | w_spi | w_str_w2k_dist | w_tci | mean | median | per90 | std | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 11 | 167.750107 | -0.243415 | -0.006419 | -0.000278 | 0.052850 | -0.003702 | 760.0 | -0.005648 | 13.986955 | 1611.938110 | -0.003823 | 16.299999 | 57.580921 | 298.0 | 3.0 | 0.078407 | 173.928513 | 42.452179 | 8.741459 | 0.097008 | 0.094664 | 0.117911 | 0.016844 |
| 1 | 1 | 10 | 186.597610 | -0.456937 | -0.003307 | -0.001944 | -0.052850 | -0.005112 | 793.0 | -0.002830 | 24.701620 | 1603.144653 | -0.004220 | 16.299999 | 18.216928 | 298.0 | 5.0 | 0.040093 | 153.324326 | 143.446518 | 7.134220 | 0.082413 | 0.082888 | 0.101135 | 0.020149 |
| 2 | 2 | 10 | 187.867950 | -0.529534 | -0.002334 | 0.000556 | -0.073177 | -0.004231 | 808.0 | -0.001522 | 28.127462 | 1601.273193 | -0.003833 | 16.299999 | 13.026308 | 298.0 | 5.0 | 0.054766 | 115.282860 | 199.080109 | 6.180274 | 0.082921 | 0.078278 | 0.113270 | 0.023337 |
| 3 | 3 | 11 | 135.514297 | -0.269037 | -0.004474 | 0.001944 | 0.264250 | -0.000881 | 877.0 | -0.003813 | 20.661793 | 1625.434448 | -0.000656 | 0.030000 | 5.122952 | 298.0 | 3.0 | 0.030000 | 23.608582 | 824.232788 | 5.899572 | 0.106816 | 0.104386 | 0.123099 | 0.014474 |
| 4 | 4 | 11 | 95.767517 | -0.042704 | -0.003501 | 0.001667 | 0.422801 | -0.003173 | 898.0 | -0.002736 | 23.023153 | 1658.049072 | -0.002913 | 16.299999 | 2.950633 | 298.0 | 2.0 | 0.037655 | 23.699802 | 1175.459473 | 5.373617 | 0.114286 | 0.117651 | 0.129462 | 0.015016 |
predictors.describe()
| fid | label | aspect | dx | dxx | dxy | dy | dyy | elv | pcurv | slope | str_2kvj_dist | tcurv | w_SlSt | w_accum | w_basin | w_dr_dir | w_lSl | w_spi | w_str_w2k_dist | w_tci | cos_asp | sin_asp | basin_shuf | mean | median | per90 | std | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 74610.000000 | 74610.000000 | 7.461000e+04 | 7.461000e+04 | 7.461000e+04 | 7.461000e+04 | 7.461000e+04 | 7.461000e+04 | 74610.000000 | 7.461000e+04 | 7.461000e+04 | 74610.000000 | 7.461000e+04 | 74610.000000 | 74610.000000 | 7.461000e+04 | 74610.000000 | 74610.000000 | 7.461000e+04 | 7.461000e+04 | 7.461000e+04 | 74610.000000 | 74610.000000 | 7.461000e+04 | 74610.000000 | 74610.000000 | 74610.000000 | 74610.000000 |
| mean | 37333.886986 | 11.610481 | 6.837265e+05 | 6.835545e+05 | 6.835545e+05 | 6.835545e+05 | 6.835545e+05 | 6.835545e+05 | 575.752379 | 6.835545e+05 | 6.835639e+05 | 1244.034957 | 6.835545e+05 | 6.898900 | 156.125340 | 1.102226e+07 | 4.388795 | 0.041021 | 6.843058e+05 | 1.101833e+07 | 6.835616e+05 | 0.149895 | 0.070254 | 1.102226e+07 | 0.126390 | 0.124655 | 0.144773 | 0.017460 |
| std | 21553.426532 | 0.961089 | 2.613611e+07 | 2.613611e+07 | 2.613611e+07 | 2.613611e+07 | 2.613611e+07 | 2.613611e+07 | 419.481320 | 2.613611e+07 | 2.613611e+07 | 831.669605 | 2.613611e+07 | 8.035924 | 11065.900632 | 1.043836e+08 | 2.454120 | 0.024518 | 2.613610e+07 | 1.043841e+08 | 2.613611e+07 | 0.700993 | 0.693699 | 1.043836e+08 | 0.033416 | 0.031926 | 0.045378 | 0.013877 |
| min | 0.000000 | 9.000000 | 0.000000e+00 | -1.344040e+00 | -1.182164e-01 | -2.553215e-02 | -1.341612e+00 | -5.341714e-02 | 8.000000 | -3.485471e-02 | 0.000000e+00 | 0.000000 | -4.527013e-02 | 0.030000 | -518632.187500 | 2.980000e+02 | -4.000000 | 0.025332 | 1.446173e-01 | 0.000000e+00 | 1.318053e+00 | -1.000000 | -1.000000 | 2.980000e+02 | 0.018881 | 0.029393 | 0.071009 | 0.002483 |
| 25% | 18669.250000 | 11.000000 | 6.651141e+01 | -2.985837e-02 | -1.551966e-03 | -5.554170e-04 | -3.658877e-02 | -1.410363e-03 | 171.000000 | -1.434810e-03 | 1.847334e+00 | 585.213623 | -1.201079e-03 | 0.030000 | 1.378385 | 1.468000e+03 | 2.000000 | 0.030000 | 2.121571e+00 | 2.781997e+02 | 5.179891e+00 | -0.532889 | -0.614763 | 1.468000e+03 | 0.106657 | 0.105575 | 0.119463 | 0.009773 |
| 50% | 37334.500000 | 11.000000 | 1.623830e+02 | 1.279920e-02 | 0.000000e+00 | 0.000000e+00 | 4.065462e-03 | 0.000000e+00 | 452.000000 | -1.332938e-04 | 4.606714e+00 | 1060.480957 | 1.762322e-19 | 0.030000 | 2.929744 | 7.130000e+03 | 5.000000 | 0.030000 | 9.361089e+00 | 8.213889e+02 | 6.182429e+00 | 0.310322 | 0.123289 | 7.130000e+03 | 0.119984 | 0.119425 | 0.133374 | 0.012945 |
| 75% | 55997.750000 | 12.000000 | 2.785243e+02 | 5.974620e-02 | 1.359604e-03 | 5.553937e-04 | 4.878521e-02 | 1.234086e-03 | 1037.000000 | 1.057664e-03 | 1.578789e+01 | 1755.921539 | 1.408627e-03 | 16.299999 | 10.037903 | 7.732000e+03 | 7.000000 | 0.040093 | 3.752013e+01 | 1.587121e+03 | 8.189266e+00 | 0.826665 | 0.732041 | 7.732000e+03 | 0.139325 | 0.138246 | 0.155657 | 0.019381 |
| max | 74664.000000 | 19.000000 | 1.000000e+09 | 1.000000e+09 | 1.000000e+09 | 1.000000e+09 | 1.000000e+09 | 1.000000e+09 | 1523.000000 | 1.000000e+09 | 1.000000e+09 | 4256.849121 | 1.000000e+09 | 16.299999 | 207631.109375 | 1.000000e+09 | 8.000000 | 0.409775 | 1.000000e+09 | 1.000000e+09 | 1.000000e+09 | 1.000000 | 1.000000 | 1.000000e+09 | 0.404548 | 0.414857 | 0.674392 | 0.238861 |
Check for and remove nan-values
#predictors.describe()
print(predictors.isnull().values.any())
predictors = predictors.dropna()
predictors.isnull().values.any()
False
False
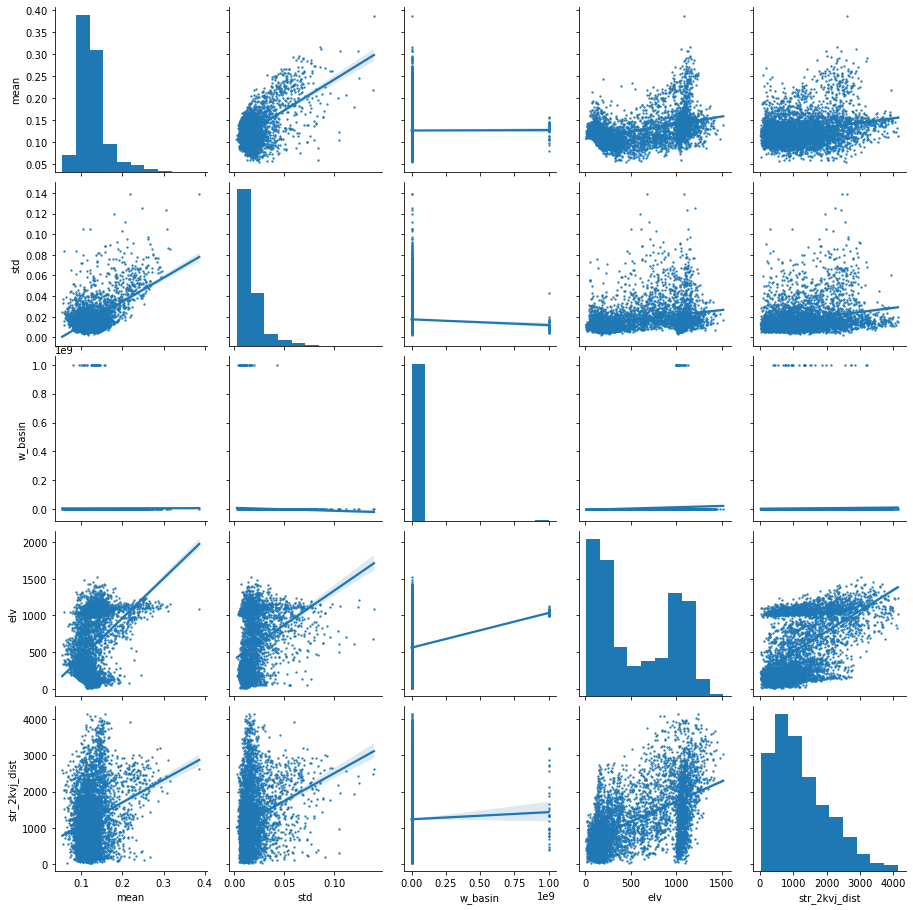
checking covariance for some variables
predictors_sample = predictors[["mean","std", "w_basin", "elv", "str_2kvj_dist"]].sample(5000)
sns.pairplot(predictors_sample , kind="reg", plot_kws=dict(scatter_kws=dict(s=2)))
plt.show()
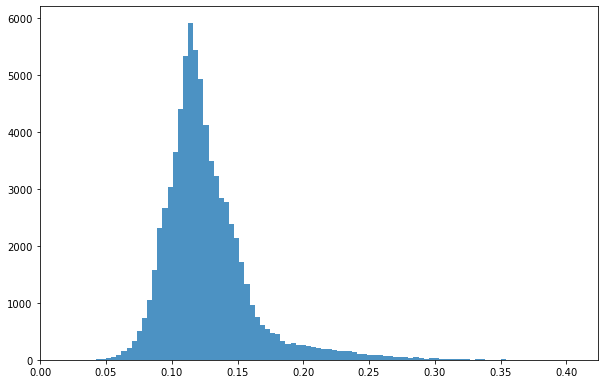
bins = np.linspace(min(predictors['mean']),max(predictors['mean']),100)
plt.hist((predictors['mean']),bins,alpha=0.8);
predictors.columns #get names
Index(['fid', 'label', 'aspect', 'dx', 'dxx', 'dxy', 'dy', 'dyy', 'elv',
'pcurv', 'slope', 'str_2kvj_dist', 'tcurv', 'w_SlSt', 'w_accum',
'w_basin', 'w_dr_dir', 'w_lSl', 'w_spi', 'w_str_w2k_dist', 'w_tci',
'cos_asp', 'sin_asp', 'basin_shuf', 'mean', 'median', 'per90', 'std'],
dtype='object')
predictors.shape
(74610, 28)
X = predictors.iloc[:,[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 15, 17, 18, 19, 20, 21, 22, 23]].values #remove savi related and stream_j_dist
Y = predictors.iloc[:,24].values #response variable
feat = predictors.iloc[:,[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 15, 17, 18, 19, 20, 21, 22, 23]].columns.values
predictors.iloc[:,[24]].columns.values
array(['mean'], dtype=object)
print(feat)
['aspect' 'dx' 'dxx' 'dxy' 'dy' 'dyy' 'elv' 'pcurv' 'slope'
'str_2kvj_dist' 'tcurv' 'w_accum' 'w_basin' 'w_lSl' 'w_spi'
'w_str_w2k_dist' 'w_tci' 'cos_asp' 'sin_asp' 'basin_shuf']
print(Y.shape)
print(X.shape)
(74610,)
(74610, 20)
Y
array([0.09700802, 0.08241346, 0.0829206 , ..., 0.13141605, 0.12182923,
0.11685393])
split data into test and training dataset
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.5, random_state=24) #id. training and testing; split 50/50
y_train = np.ravel(Y_train)
y_test = np.ravel(Y_test)
2.7.6.2. Random forest
Random forest is defined and then run with different settings to find the best model.
rf = RandomForestRegressor(random_state = 42)
rf.get_params()#default parameters - should be tuned! - not needed in R
{'bootstrap': True,
'ccp_alpha': 0.0,
'criterion': 'mse',
'max_depth': None,
'max_features': 'auto',
'max_leaf_nodes': None,
'max_samples': None,
'min_impurity_decrease': 0.0,
'min_impurity_split': None,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'n_estimators': 100,
'n_jobs': None,
'oob_score': False,
'random_state': 42,
'verbose': 0,
'warm_start': False}
# first tried with this default setting rfReg = RandomForestRegressor(min_samples_leaf=50, oob_score=True)
# after running chunks below, these settings seems to better fit the data.
rfReg = RandomForestRegressor(n_estimators=80, min_samples_leaf=20, max_depth=100, max_features=0.5, random_state=42 , oob_score = True)
rfReg.fit(X_train, y_train);
dic_pred = {}
dic_pred['train'] = rfReg.predict(X_train)
dic_pred['test'] = rfReg.predict(X_test)
pearsonr_all = [pearsonr(dic_pred['train'],y_train)[0],pearsonr(dic_pred['test'],y_test)[0]] #training vs pred R
pearsonr_all
[0.9151073853228917, 0.8930071550321135]
# checking the oob score
rfReg.oob_score_
0.7825391349776363
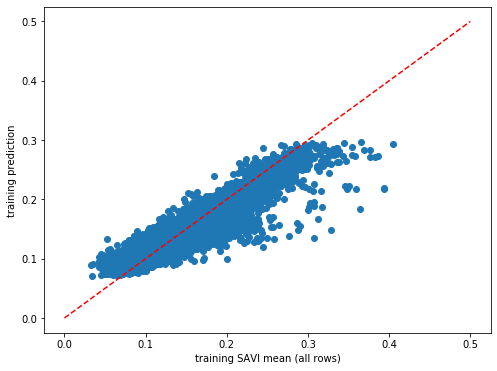
plt.rcParams["figure.figsize"] = (8,6)
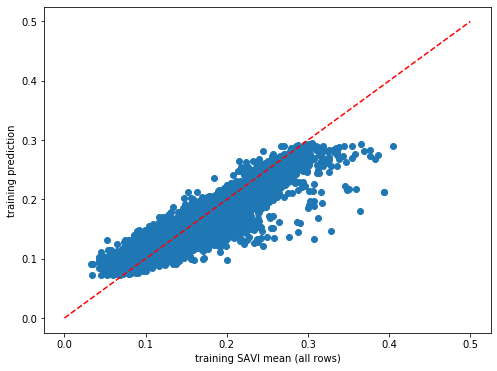
plt.scatter(y_train,dic_pred['train'])
plt.xlabel('training SAVI mean (all rows)')
plt.ylabel('training prediction')
ident = [0, 0.5]
plt.plot(ident,ident,'r--')
[<matplotlib.lines.Line2D at 0x7f374ad840d0>]
impt = [rfReg.feature_importances_, np.std([tree.feature_importances_ for tree in rfReg.estimators_],axis=1)]
ind = np.argsort(impt[0])
ind
array([13, 5, 3, 19, 7, 10, 2, 18, 0, 17, 11, 14, 16, 4, 8, 1, 15,
9, 6, 12])
#feature importance
plt.rcParams["figure.figsize"] = (6,12)
plt.barh(range(len(feat)),impt[0][ind],color="b", xerr=impt[1][ind], align="center")
plt.yticks(range(len(feat)),feat[ind]);
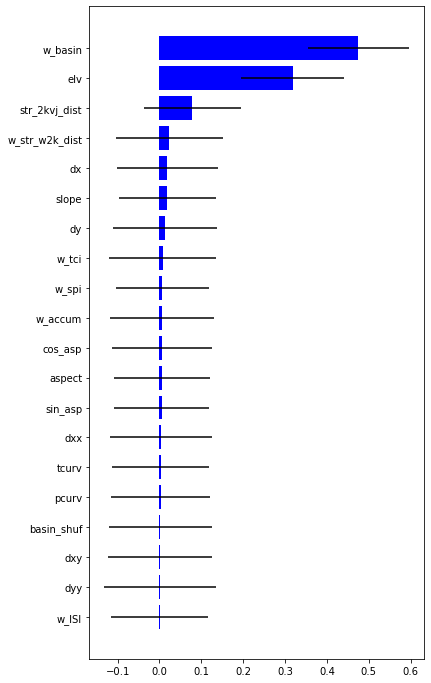
src1 = rasterio.open("/home/user/my_SE_data/exercise/grassout/w_basin.tif")
src2 = rasterio.open("/home/user/my_SE_data/exercise/grassout/elv.tif")
src3 = rasterio.open("/home/user/my_SE_data/exercise/grassout/str_2kvj_dist.tif")
src4 = rasterio.open("/home/user/my_SE_data/exercise/landsat/mean_pyjeo.tif")
fig, (src1p,src2p,src3p, src4p) = plt.subplots(1,4, figsize=(21,7))
show(src1, ax=src1p, title='basins' , vmin=0, vmax=10000, cmap='gist_rainbow' )
show(src2, ax=src2p, title='elevation' , vmin=0, vmax=1500, cmap='gist_rainbow' )
show(src3, ax=src3p, title='str_2kvj_dist' , vmin=0, vmax=5000, cmap='gist_rainbow' )
show(src4, ax=src4p, title='mean SAVI' , vmin=0, vmax=1, cmap='gist_rainbow' )
<matplotlib.axes._subplots.AxesSubplot at 0x7f374abeb910>

2.7.6.3. Random Forest tuning
“max_features”: number of features to consider when looking for the best split.
“max_samples”: number of samples to draw from X to train each base estimator.
“n_estimators”: identify the number of trees that must grow. It must be large enough so that the error is stabilized. Defoult 100.
“max_depth”: max number of levels in each decision tree.
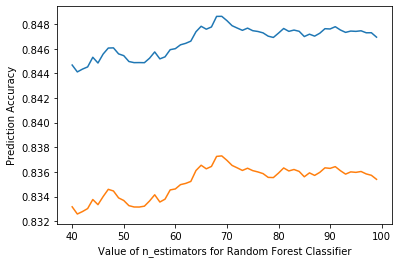
scores =[]
for k in range(40, 100):
rfReg = RandomForestRegressor(n_estimators=k, min_samples_leaf=50, max_features=0.33,max_depth=150,max_samples=0.7,n_jobs=-1,random_state=42 , oob_score = True)
rfReg.fit(X_train, y_train);
dic_pred = {}
dic_pred['train'] = rfReg.predict(X_train)
dic_pred['test'] = rfReg.predict(X_test)
scores.append([pearsonr(dic_pred['train'],y_train)[0],pearsonr(dic_pred['test'],y_test)[0]])
%matplotlib inline
plt.plot(range(40, 100), scores)
plt.xlabel('Value of n_estimators for Random Forest Classifier')
plt.ylabel('Prediction Accuracy')
Text(0, 0.5, 'Prediction Accuracy')
scores =[]
for k in [50, 100, 150]:
rfReg = RandomForestRegressor(n_estimators=80, min_samples_leaf=50, max_features=0.33, max_depth=k, max_samples=0.7,n_jobs=-1,random_state=42 , oob_score = True)
rfReg.fit(X_train, y_train);
dic_pred = {}
dic_pred['train'] = rfReg.predict(X_train)
dic_pred['test'] = rfReg.predict(X_test)
scores.append([pearsonr(dic_pred['train'],y_train)[0],pearsonr(dic_pred['test'],y_test)[0]])
%matplotlib inline
plt.plot([50, 100, 150], scores)
plt.xlabel('Value of n_estimators for Random Forest Classifier')
plt.ylabel('Prediction Accuracy')
Text(0, 0.5, 'Prediction Accuracy')

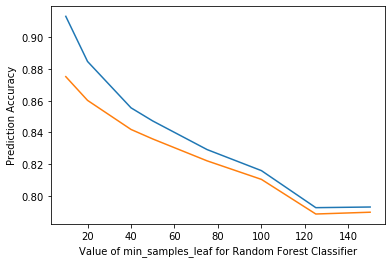
scores =[]
for k in [10, 20, 40, 50, 75, 100, 125, 150]:
rfReg = RandomForestRegressor(n_estimators=80, min_samples_leaf=k, max_features=0.33, max_depth=50, max_samples=0.7,n_jobs=-1,random_state=42 , oob_score = True)
rfReg.fit(X_train, y_train);
dic_pred = {}
dic_pred['train'] = rfReg.predict(X_train)
dic_pred['test'] = rfReg.predict(X_test)
scores.append([pearsonr(dic_pred['train'],y_train)[0],pearsonr(dic_pred['test'],y_test)[0]])
%matplotlib inline
plt.plot([10, 20, 40, 50, 75, 100, 125, 150], scores)
plt.xlabel('Value of min_samples_leaf for Random Forest Classifier')
plt.ylabel('Prediction Accuracy')
# rfReg = RandomForestRegressor(n_estimators=80, min_samples_leaf=80, max_features=0.33, max_depth=50, max_samples=0.7,n_jobs=-1,random_state=42 , oob_score = True)
Text(0, 0.5, 'Prediction Accuracy')
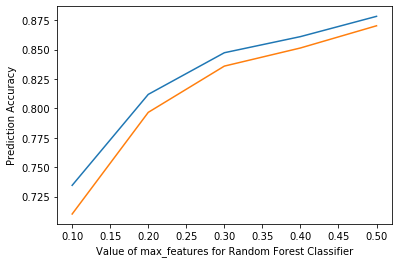
scores =[]
for k in [0.1, 0.2, 0.3, 0.4, 0.5]:
rfReg = RandomForestRegressor(n_estimators=80, min_samples_leaf=50, max_features=k, max_depth=50, max_samples=0.7,n_jobs=-1,random_state=42 , oob_score = True)
rfReg.fit(X_train, y_train);
dic_pred = {}
dic_pred['train'] = rfReg.predict(X_train)
dic_pred['test'] = rfReg.predict(X_test)
scores.append([pearsonr(dic_pred['train'],y_train)[0],pearsonr(dic_pred['test'],y_test)[0]])
%matplotlib inline
plt.plot([0.1, 0.2, 0.3, 0.4, 0.5], scores)
plt.xlabel('Value of max_features for Random Forest Classifier')
plt.ylabel('Prediction Accuracy')
# rfReg = RandomForestRegressor(n_estimators=80, min_samples_leaf=80, max_features=0.33, max_depth=50, max_samples=0.7,n_jobs=-1,random_state=42 , oob_score = True)
Text(0, 0.5, 'Prediction Accuracy')
2.7.6.4. Predict on the raster using pyspatialml
pip install Pyspatialml
prediction with most important variables
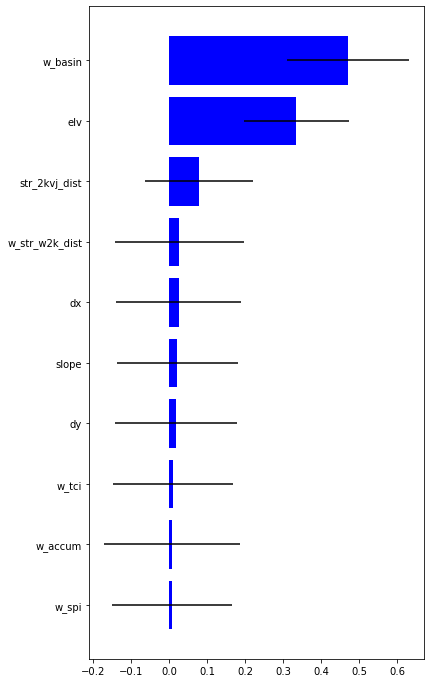
X = predictors[['elv', 'w_basin', 'str_2kvj_dist', 'w_str_w2k_dist', 'dx', 'dy', 'slope', 'w_tci', 'w_spi', 'w_accum']] #remove savi related and stream_j_dist
Y = predictors[['mean']] #response variable
feat = predictors[['elv', 'w_basin', 'str_2kvj_dist', 'w_str_w2k_dist', 'dx', 'dy', 'slope', 'w_tci', 'w_spi', 'w_accum']].columns.values
predictors[['mean']].columns.values
array(['mean'], dtype=object)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.5, random_state=24) #id. training and testing; split 50/50
y_train = np.ravel(Y_train)
y_test = np.ravel(Y_test)
rf = RandomForestRegressor(random_state = 42)
rfReg = RandomForestRegressor(n_estimators=80, min_samples_leaf=20, max_depth=100, max_features=0.5, random_state=42 , oob_score = True)
rfReg.fit(X_train, y_train);
dic_pred = {}
dic_pred['train'] = rfReg.predict(X_train)
dic_pred['test'] = rfReg.predict(X_test)
pearsonr_all = [pearsonr(dic_pred['train'],y_train)[0],pearsonr(dic_pred['test'],y_test)[0]] #training vs pred R
pearsonr_all
[0.9133764136610967, 0.8939919955832134]
# checking the oob score
rfReg.oob_score_
0.7855745474283174
plt.rcParams["figure.figsize"] = (8,6)
plt.scatter(y_train,dic_pred['train'])
plt.xlabel('training SAVI mean (all rows)')
plt.ylabel('training prediction')
ident = [0, 0.5]
plt.plot(ident,ident,'r--')
[<matplotlib.lines.Line2D at 0x7f371abf8910>]
impt = [rfReg.feature_importances_, np.std([tree.feature_importances_ for tree in rfReg.estimators_],axis=1)]
ind = np.argsort(impt[0])
ind
array([8, 9, 7, 5, 6, 4, 3, 2, 0, 1])
#feature importance
plt.rcParams["figure.figsize"] = (6,12)
plt.barh(range(len(feat)),impt[0][ind],color="b", xerr=impt[1][ind], align="center")
plt.yticks(range(len(feat)),feat[ind]);
import and stack datasets for prediction
#Import datasets
elv = rasterio.open("/home/user/my_SE_data/exercise/grassout/elv.tif")
w_basin = rasterio.open("/home/user/my_SE_data/exercise/grassout/w_basin.tif")
str_2kvj_dist = rasterio.open("/home/user/my_SE_data/exercise/grassout/str_2kvj_dist.tif")
w_str_w2k_dist = rasterio.open("/home/user/my_SE_data/exercise/grassout/w_str_w2k_dist.tif")
dx = rasterio.open("/home/user/my_SE_data/exercise/grassout/dx.tif")
dy = rasterio.open("/home/user/my_SE_data/exercise/grassout/dy.tif")
slope = rasterio.open("/home/user/my_SE_data/exercise/grassout/slope.tif")
w_tci = rasterio.open("/home/user/my_SE_data/exercise/grassout/w_tci.tif")
w_spi = rasterio.open("/home/user/my_SE_data/exercise/grassout/w_spi.tif")
w_accum = rasterio.open("/home/user/my_SE_data/exercise/grassout/w_accum.tif")
predictors_rasters = [elv, w_basin, str_2kvj_dist, w_str_w2k_dist, dx, dy, slope, w_tci, w_spi, w_accum]
stack = Raster(predictors_rasters)
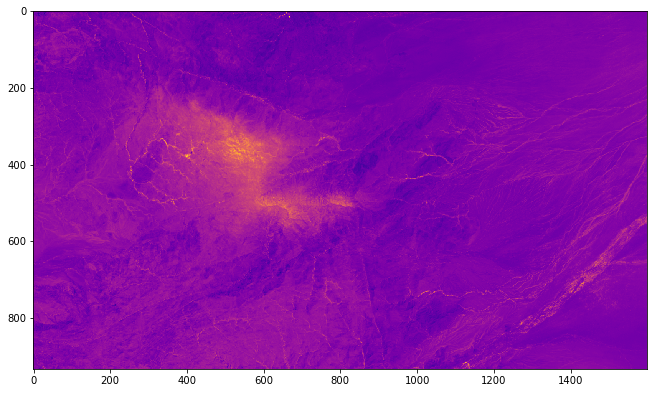
result = stack.predict(estimator=rfReg, dtype='float64', nodata=-1)
# plot regression result
plt.rcParams["figure.figsize"] = (12,12)
result.iloc[0].cmap = "plasma"
result.plot()
plt.show()

import rasterio
from matplotlib import pyplot
src = rasterio.open("/home/user/my_SE_data/exercise/landsat/mean_pyjeo.tif")
pyplot.imshow(src.read(1), cmap='plasma')
pyplot.show()
2.7.7. 5 Follow up
This case study was primarily for learning the tools and how bash, python, grass etc can be combined in one environment. Obviously there are many improvements that can be done for the case study itself. Some are listed below
consider more explanatory variables and remove w_basin
test deep learning methods
look into other response variables that better catch the variability of the environment and try to distinguish among the long-lived and short-lived vegetation
expand the area to include larger environmental variability